|
I am an assistant professor at UBC, a member of the Vector Institute, and a Canada CIFAR AI Chair. I earned my PhD in computer science from UC Berkeley in 2019 where I was advised by Trevor Darrell as part of BAIR. Before the PhD, I earned dual degrees in computer science (artificial intelligence concentration) and psychology at UMass Amherst advised by Erik Learned-Miller. After the PhD, I spent a wonderful year in Cambridge, MA as a research scientist at Adobe and visiting scientist at MIT. Next I spent four deep years as a research scientist then senior research scientist at Google DeepMind in London and San Francisco before returning to academia.
I believe in DIY science and open tooling for research and engineering.
shelhamer@imaginarynumber.net / Google Scholar / GitHub / CV |

|
News
|
|
I am interested in machine learning and computer vision, in particular adaptation and adaptive computation for robustness and efficiency during deployment along with the reconciliation of visual structure with deep learning (to learn more, not less). In recent orbits I am working more and more on AI for science and sustainability through remote sensing and satellites. See my scholar page for a full list of projects. |
| Latest Projects |

|
Galileo is a single generalist model of remote sensing data for many kinds of inputs and tasks. This data is diverse, with multiple modalities (optical, radar, ...), shapes (pixel time series, image time series, single images), and spatiotemporal scales (local, global). Our unified self-supervised pre-training achieves transfer on 10 benchmarks with or without fine-tuning. |

|
Adaptive Randomized Smoothing (ARS) certifies test-time updates against adversarial attack. Our theory establishes the sound adaptive composition of general and high-dimensional functions of noisy inputs. In practice, ARS learns to mask the noise for randomized smoothing given the input with results on CelebA, CIFAR-10, and ImageNet. |

|
LookWhere distills self-supervision into efficient adaptive computation by learning where to look (from attention maps) and what to see (from deep representations). It is fast to fine-tune and use: it reduces FLOPs 34x and time 6x for sparse recognition on Traffic Signs and time 1.36x for standard recognition on ImageNet classification and ADE20K segmentation. |

|
Jumbo makes vision transformers (ViTs) faster and more accurate by altering just one token: it makes a wider CLS token, splits it for self-attention, then joins it for its own wider FFN. Jumbo improves on registers in accuracy and efficient architectures in speed, while still a plain ViT, with results on ImageNet-1K and 21K, time series, and self-supervision by MAE. |

|
Size matters: bigger models tend to make better predictions. To adjust size, we pair a larger model with a smaller model as a "sidekick" that can help surprisingly much when combined in the right way. Asymmetric Duos improve accuracy, uncertainty quantification, and selective classification metrics with only ~10−20% more computation at ImageNet scale. |

|
Reservoir test-time adaptation populates and updates a fully test-time reservoir of domain-specialist models for robust long-horizon adaptation. Our multi-modeling addresses issues with single model updates (catastrophic forgetting, inter-domain interference, and drift) on recurring and changing domains with state-of-the-art accuracy on ImageNet-C and more. |

|
Embedding Fields are learned from remote sensing data then computed as an accessible substitute for remote sensing data. In effect the model is delivered as data, indexed by space (lat, lon) and time (year), for use in analysis without the computational or technical obstacles of directly working with deep networks and remote sensing data products. |
| Selected Projects |

|
Tent ⛺️ helps a model adapt itself to changing conditions ☀️ 🌧 ❄️ by updating on new and different data during testing without altering training or requiring more supervision. Tent adapts by test entropy minimization: optimizing the model for confidence as measured by the entropy of its predictions. |

|
Model soups mix parameters from related fine-tunings into a single model to improve predictions. We mix soups with different seasonings (= models fine-tuned for different types of robustness) to cope with various shifts at test time given few shot supervision. The right seasoning depends on the shift, which we can quickly mix without gradient optimization. |

|
We can optimize filter size by reconciling signal process and deep learning.
Composing structured Gaussian filters with free-form filters, and learning both, is a strictly more general parameterization.
In effect this controls the degree of locality:
|

|
Fully convolutional networks are machines for image-to-image learning and inference.
|
|
Caffe is a deep learning framework made with expression, speed, and modularity in mind. The deep learning shift was in part a sea change on the wave of open science and toolkits, including Caffe and its Model Zoo. |
| More Projects |

|
Most methods for test-time adaptation update the source model by (re-)training on each target domain. We update the target data instead, and project all test inputs toward the source domain with a generative diffusion model. Our input updates help on small batches, data in dependent orders, or on data with multiple corruptions. |

|
Adaptive test-time defenses alter inference by iteratively updating the input x or parameters 𝜃 of the model to improve robustness to adversarial attack. Or do they? Our careful case study shows that more updates are needed to improve on the robustness of adversarial training by test-time updates. |

|
Anytime inference requires a model to make a progression of predictions which might be halted at any time. Our anytime dense prediction with confidence method (ADP-C) prioritizes computation by its own predictions layer-by-layer. ADP-C reduces FLOPS to 44-59%, maintains accuracy, and improves on iterative DEQs and sparse feature sampling. |
|
Infinite mixture prototypes adaptively adjust model capacity by representing classes as sets of clusters and inferring their number. This handles both simple and complex few-shot tasks, and improves alphabet recognition accuracy by 25% absolute over uni-modal prototypes. |

|
Extracting a latent task representation from local supervision allows for non-local propagation within and across images with quick updates for real-time interaction. (Note: this subsumes our ICLRW'18 paper on conditional networks). |
|
Deepening aggregation, the iterative and hierarchical merging of features across layers, improves recognition and resolution. |
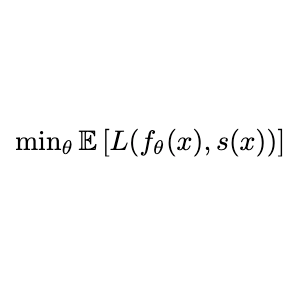
|
Loss is where you find it. With self-supervision for representation learning, experience without reward need not be so unrewarding for reinforcement learning. |
|
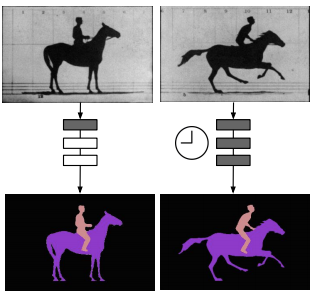
Adaptively computing layers according to their rate of change improves the efficiency of video processing without sacrificing accuracy. |
|
|
|
Area Chair: CVPR (2021, 2023, 2024, 2025), NeurIPS (2023, 2024, 2025), ICLR (2024, 2025), ICML (2024, 2025), ICCV (2021, 2023, 2025), ECCV (2024).
|